Abstract

Recently, several approaches have emerged for generating neural representations with multiple levels of detail (LODs). LODs can improve the rendering by using lower resolutions and smaller model sizes when appropriate. However, existing methods generally focus on a few discrete LODs which suffer from aliasing and flicker artifacts as details are changed and limit their granularity for adapting to resource limitations. In this paper, we propose a method to encode light field networks with continuous LODs, allowing for finely tuned adaptations to rendering conditions. Our training procedure uses summed-area table filtering allowing efficient and continuous filtering at various LODs. Furthermore, we use saliency-based importance sampling which enables our light field networks to distribute their capacity, particularly limited at lower LODs, towards representing the details viewers are most likely to focus on. Incorporating continuous LODs into neural representations enables progressive streaming of neural representations, decreasing the latency and resource utilization for rendering.
Downloads



Rendered Examples
Discrete-scale LFN

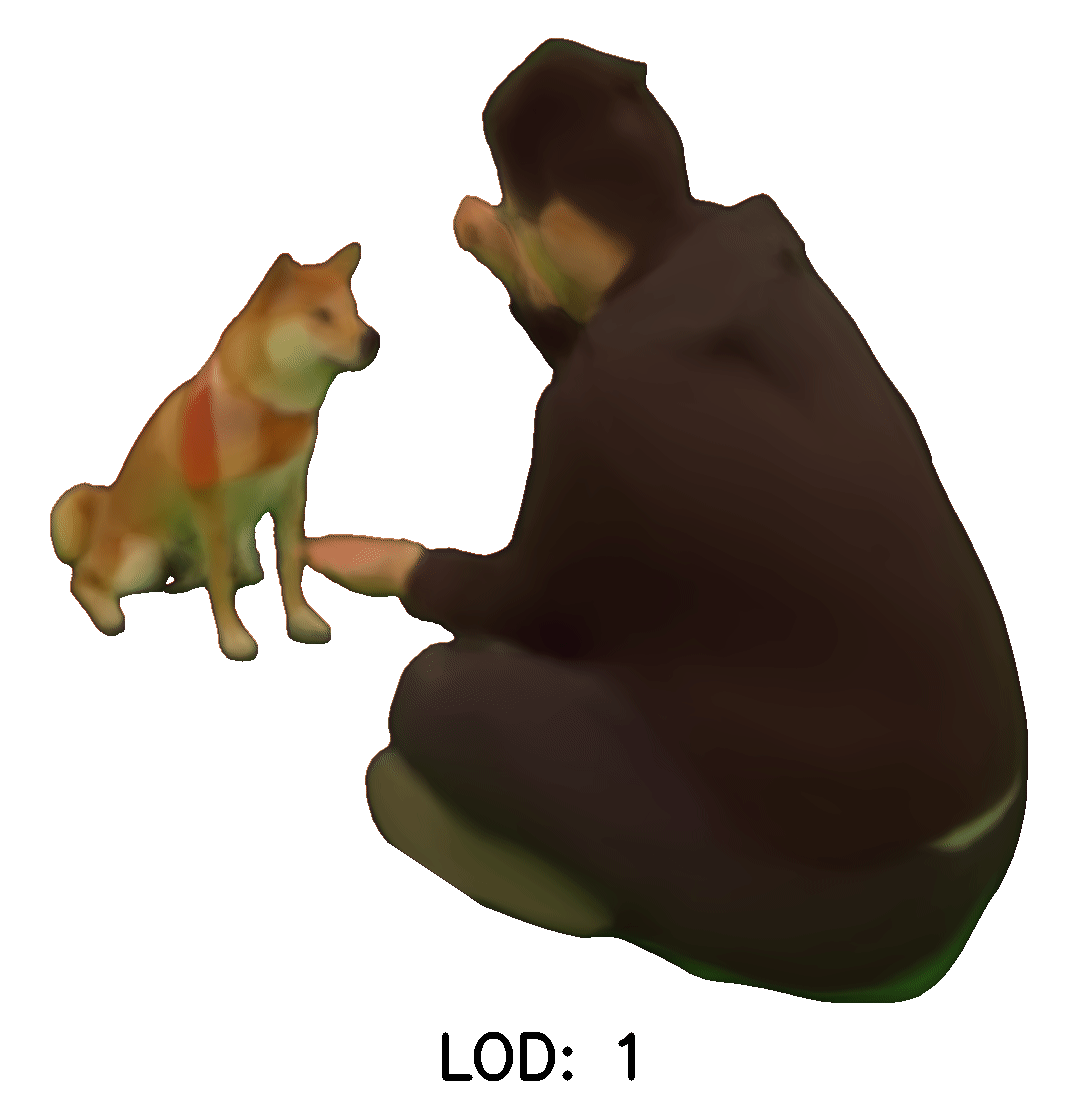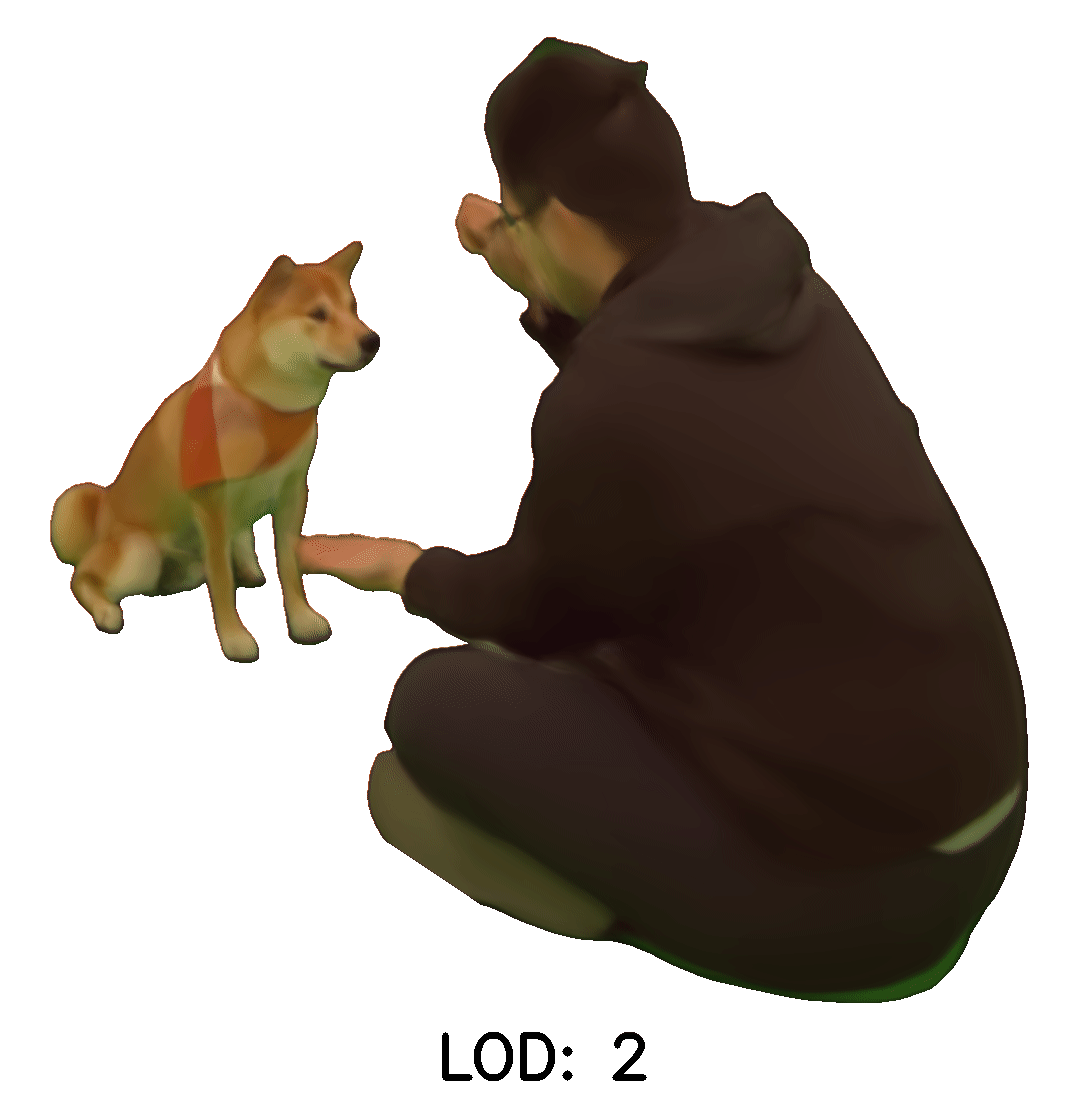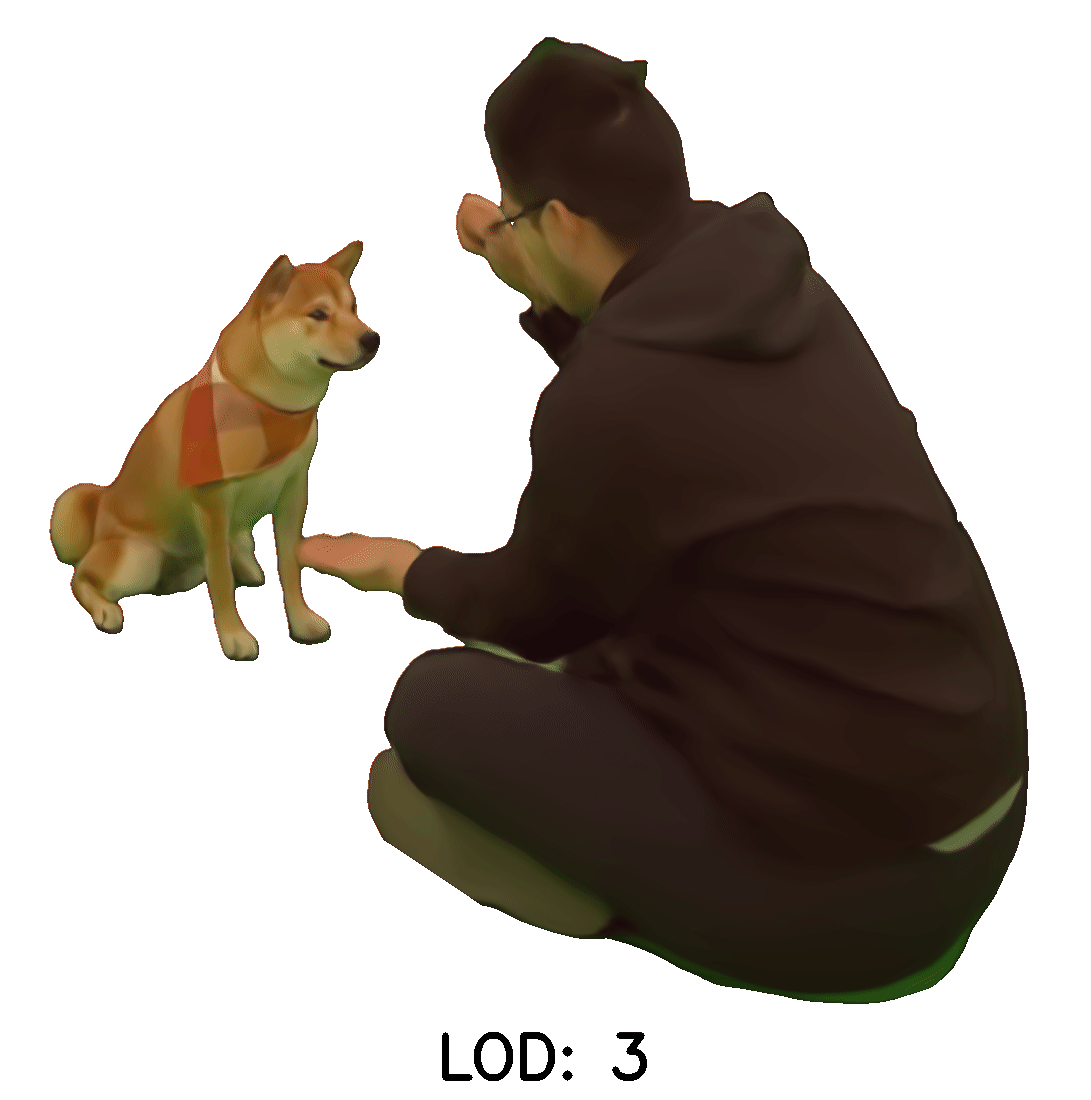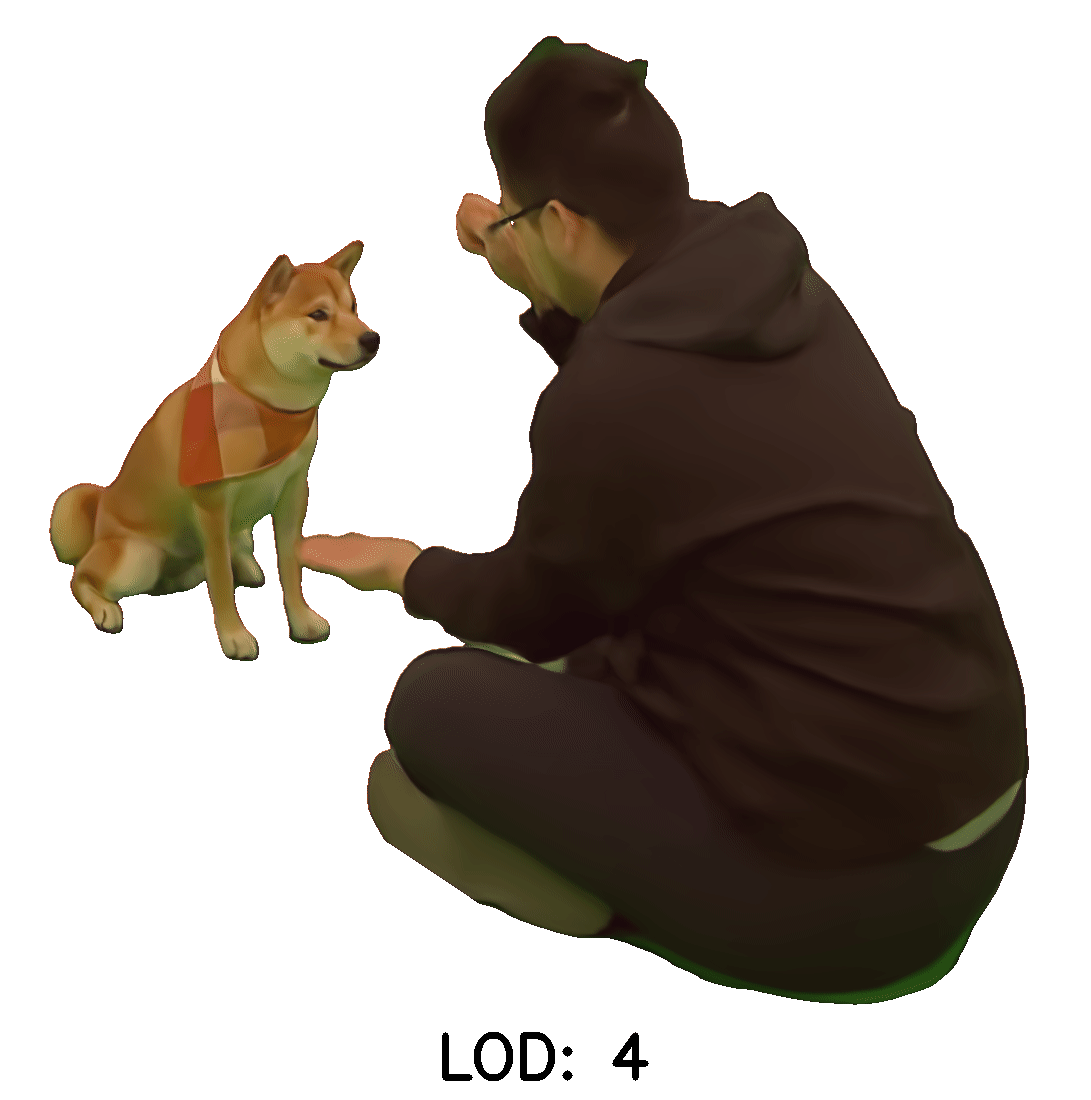



Continuous LOD LFN
The following examples were rendered using our light field network with continuous levels of detail.
The first column shows transitions across levels of detail from a fixed viewpoint
The second column shows renders first at the highest level of detail and then at varying lower levels of detail.
| Fixed Camera Transition | Camera Loop + Transition |
Citation
@inproceedings{li2023continuouslodlfn,
author = {David Li and Brandon Yushan Feng and Amitabh Varshney},
title = {Continuous Levels of Detail for Light Field Networks},
booktitle = {34th British Machine Vision Conference 2023, {BMVC} 2023, Aberdeen, UK, November 20-24, 2023},
publisher = {{BMVA}},
year = {2023},
url = {https://papers.bmvc2023.org/0139.pdf}
}
David Li, Brandon Y. Feng, and Amitabh Varshney. Continuous Levels of Detail for Light Field Networks. In 34th British Machine Vision Conference 2023 (BMVC 2023)